


Agregátor RSS
This Week’s Awesome Tech Stories From Around the Web (Through July 27)
ARTIFICIAL INTELLIGENCE
Google DeepMind’s New AI Systems Can Now Solve Complex Math Problems
Rhiannon Williams | MIT Technology Review
“AI models can easily generate essays and other types of text. However, they’re nowhere near as good at solving math problems, which tend to involve logical reasoning—something that’s beyond the capabilities of most current AI systems. But that may finally be changing. Google DeepMind says it has trained two specialized AI systems to solve complex math problems involving advanced reasoning.”
archive page
COMPUTINGThis Startup Is Building the Country’s Most Powerful Quantum Computer on Chicago’s South Side
Adam Bluestein | Fast Company
“PsiQuantum’s approach is radically different from that of its competitors. It’s relying on cutting-edge ‘silicon photonics’ to manipulate single particles of light for computation. And instead of taking an incremental approach to building a supercomputer, it’s focused entirely on coming out of the gate with a full-blown, ‘fault tolerant’ system that will be far larger than any quantum computer built to date. The company has vowed to have its first system operational by late 2027, years earlier than other projections.”
The Race for the Next Ozempic
Emily Mullin | Wired
“These drugs are now wildly popular, in shortage as a result, and hugely profitable for the companies making them. Their success has sparked a frenzy among pharmaceutical companies looking for the next blockbuster weight-loss drug. Researchers are now racing to develop new anti-obesity medications that are more effective, more convenient, or produce fewer side effects than the ones currently on the market.”
Watch a Robot Peel a Squash With Human-Like Dexterity
Alex Wilkins | New Scientist
“Pulkit Agrawal at the Massachusetts Institute of Technology and his colleagues have developed a robotic system that can rotate different types of fruit and vegetable using its fingers on one hand, while the other arm is made to peel.”
Here’s What Happens When You Give People Free Money
Paresh Dave | Wired
“The initial results from what OpenResearch, an Altman-funded research lab, describes as the most comprehensive study on ‘unconditional cash’ show that while the grants had their benefits and weren’t spent on items such as drugs and alcohol, they were hardly a panacea for treating some of the biggest concerns about income inequality and the prospect of AI and other automation technologies taking jobs.”
Meta Releases the Biggest and Best Open-Source AI Model Yet
Alex Heath | The Verge
“Meta is releasing Llama 3.1, the largest-ever open-source AI model, which the company claims outperforms GPT-4o and Anthropic’s Claude 3.5 Sonnet on several benchmarks. …CEO Mark Zuckerberg now predicts that Meta AI will be the most widely used assistant by the end of this year, surpassing ChatGPT.”
US Solar Production Soars by 25 Percent in Just One Year
John Timmer | Ars Technica
“In terms of utility-scale production, the first five months of 2024 saw it rise by 29 percent compared to the same period in the year prior. Small-scale solar was ‘only’ up by 18 percent, with the combined number rising by 25.3 percent. …It’s worth noting that this data all comes from before some of the most productive months of the year for solar power; overall, the EIA is predicting that solar production could rise by as much as 42 percent in 2024.”
SearchGPT Is OpenAI’s Direct Assault on Google
Reece Rogers and Will Knight | Wired
“After months of speculation about its search ambitions, OpenAI has revealed SearchGPT, a ‘prototype’ search engine that could eventually help the company tear off a slice of Google’s lucrative business. OpenAI said that the new tool would help users find what they are looking for more quickly and easily by using generative AI to gather links and answer user queries in a conversational tone.”
Wafer-Thin Light Sail Could Help Us Reach Another Star Sooner
Alex Wilkins | New Scientist
“A light sail designed using artificial intelligence is about 1000 times thinner than a human hair and weighs as much as a grain of sand—and it could help us create a spacecraft capable of reaching another star sooner than we thought.”
AI Can’t Make Music
Matteo Wong | The Atlantic
“While AI models are starting to replicate musical patterns, it is the breaking of rules that tends to produce era-defining songs. Algorithms ‘are great at fulfilling expectations but not good at subverting them, but that’s what often makes the best music,’ Eric Drott, a music-theory professor at the University of Texas at Austin, told me.”
Image Credit: David Clode / Unsplash
Kategorie: Transhumanismus
China Demonstrates the First Entirely Meltdown-Proof Nuclear Reactor
Efforts to expand nuclear power have long been stymied by fears of a major nuclear meltdown. A new Chinese reactor design is the first full-scale demonstration that’s entirely meltdown-proof.
Despite the rapid rise of renewable energy, many argue that nuclear power still has an important role to play in the race to decarbonize our supply of electricity. But incidents like Chernobyl and Fukushima have made people understandably wary.
The latest nuclear reactor designs are far safer than those of previous generations, but they still carry the risk of a nuclear meltdown. This refers to when a plant’s cooling system fails, often due to power supplies being cut off, leading to runaway overheating in the core. This can cause an explosion that breaches containment units and spreads radioactive material far and wide.
But now, researchers in China have carried out tests to prove that a new kind of reactor design is essentially impervious to meltdowns. In a paper in Joule, they describe a test in which they cut power to a live nuclear plant—and the plant was able to passively cool itself.
“The responses of nuclear power and temperatures within different reactor structures show that the reactors can be cooled down naturally without active intervention,” the authors write. “The results of the tests manifest the existence of commercial-scale inherent safety for the first time.”
The researchers from Tsinghua University carried out the test on the 200-megawatt High-Temperature Gas-Cooled Reactor Pebble-Bed Module (HTR-PM) in Shandong, which became commercially operational last December. The plant’s novel design replaces the fuel rods found in conventional reactor designs with a large number of “pebbles.” Each of these is a couple of inches across and made up of graphite with a small amount of uranium fuel inside.
The approach significantly reduces the energy density of the reactor’s fuel, making it easier for heat to dissipate naturally if cooling systems fail. Although small prototype reactors have been built in China and Germany, a full-scale demonstration of the technology’s safety had yet to happen.
To put the new reactor to the test, the researchers deliberately cut power to both of the plant’s reactor modules and observed the results. Both modules cooled down naturally without any intervention in roughly 35 hours. The researchers claim this is proof the design is “inherently safe” and should significantly reduce requirements for safety systems in future reactors.
The design does result in power generation costs roughly 20 percent higher than conventional reactors, the researchers admit. But they believe this will come down if and when the technology goes into mass production.
China isn’t the only country building such reactors. American company X-Energy has designed an 80-megawatt pebble-bed reactor called the Xe-100 and is currently waiting for a decision on its license to operate from the Nuclear Regulatory Commission.
However, as New Scientist notes, it’s not possible to retrofit existing plants with this technology, which means the risk of meltdowns from older plants remains. And given the huge amount of time and money it typically takes to build a nuclear power plant, it’s unlikely the technology will make up a significant chunk of the world’s nuclear fleet anytime soon.
But by proving it’s possible to build a meltdown-proof reactor, the researchers have disarmed one of the major arguments against using nuclear power to tackle the climate crisis.
Image Credit: Tsinghua University
Kategorie: Transhumanismus
This Is What Could Happen if AI Content Is Allowed to Take Over the Internet
Generative AI is a data hog.
The algorithms behind chatbots like ChatGPT learn to create human-like content by scraping terabytes of online articles, Reddit posts, TikTok captions, or YouTube comments. They find intricate patterns in the text, then spit out search summaries, articles, images, and other content.
For the models to become more sophisticated, they need to capture new content. But as more people use them to generate text and then post the results online, it’s inevitable that the algorithms will start to learn from their own output, now littered across the internet. That’s a problem.
A study in Nature this week found a text-based generative AI algorithm, when heavily trained on AI-generated content, produces utter nonsense after just a few cycles of training.
“The proliferation of AI-generated content online could be devastating to the models themselves,” wrote Dr. Emily Wenger at Duke University, who was not involved in the study.
Although the study focused on text, the results could also impact multimodal AI models. These models also rely on training data scraped online to produce text, images, or videos.
As the usage of generative AI spreads, the problem will only get worse.
The eventual end could be model collapse, where AI increasing fed data generated by AI is overwhelmed by noise and only produces incoherent baloney.
Hallucinations or Breakdown?It’s no secret generative AI often “hallucinates.” Given a prompt, it can spout inaccurate facts or “dream up” categorically untrue answers. Hallucinations could have serious consequences, such as a healthcare AI incorrectly, but authoritatively, identifying a scab as cancer.
Model collapse is a separate phenomenon, where AI trained on its own self-generated data degrades over generations. It’s a bit like genetic inbreeding, where offspring have a greater chance of inheriting diseases. While computer scientists have long been aware of the problem, how and why it happens for large AI models has been a mystery.
In the new study, researchers built a custom large language model and trained it on Wikipedia entries. They then fine-tuned the model nine times using datasets generated from its own output and measured the quality of the AI’s output with a so-called “perplexity score.” True to its name, the higher the score, the more bewildering the generated text.
Within just a few cycles, the AI notably deteriorated.
In one example, the team gave it a long prompt about the history of building churches—one that would make most human’s eyes glaze over. After the first two iterations, the AI spewed out a relatively coherent response discussing revival architecture, with an occasional “@” slipped in. By the fifth generation, however, the text completely shifted away from the original topic to a discussion of language translations.
The output of the ninth and final generation was laughably bizarre:
“architecture. In addition to being home to some of the world’s largest populations of black @-@ tailed jackrabbits, white @-@ tailed jackrabbits, blue @-@ tailed jackrabbits, red @-@ tailed jackrabbits, yellow @-.”
Interestingly, AI trained on self-generated data often ends up producing repetitive phrases, explained the team. Trying to push the AI away from repetition made the AI’s performance even worse. The results held up in multiple tests using different prompts, suggesting it’s a problem inherent to the training procedure, rather than the language of the prompt.
Circular TrainingThe AI eventually broke down, in part because it gradually “forgot” bits of its training data from generation to generation.
This happens to us too. Our brains eventually wipe away memories. But we experience the world and gather new inputs. “Forgetting” is highly problematic for AI, which can only learn from the internet.
Say an AI “sees” golden retrievers, French bulldogs, and petit basset griffon Vendéens—a far more exotic dog breed—in its original training data. When asked to make a portrait of a dog, the AI would likely skew towards one that looks like a golden retriever because of an abundance of photos online. And if subsequent models are trained on this AI-generated dataset with an overrepresentation of golden retrievers, they eventually “forget” the less popular dog breeds.
“Although a world overpopulated with golden retrievers doesn’t sound too bad, consider how this problem generalizes to the text-generation models,” wrote Wenger.
Previous AI-generated text already swerves towards well-known concepts, phrases, and tones, compared to other less common ideas and styles of writing. Newer algorithms trained on this data would exacerbate the bias, potentially leading to model collapse.
The problem is also a challenge for AI fairness across the globe. Because AI trained on self-generated data overlooks the “uncommon,” it also fails to gauge the complexity and nuances of our world. The thoughts and beliefs of minority populations could be less represented, especially for those speaking underrepresented languages.
“Ensuring that LLMs [large language models] can model them is essential to obtaining fair predictions—which will become more important as generative AI models become more prevalent in everyday life,” wrote Wenger.
How to fix this? One way is to use watermarks—digital signatures embedded in AI-generated data—to help people detect and potentially remove the data from training datasets. Google, Meta, and OpenAI have all proposed the idea, though it remains to be seen if they can agree on a single protocol. But watermarking is not a panacea: Other companies or people may choose not to watermark AI-generated outputs or, more likely, can’t be bothered.
Another potential solution is to tweak how we train AI models. The team found that adding more human-generated data over generations of training produced a more coherent AI.
All this is not to say model collapse is imminent. The study only looked at a text-generating AI trained on its own output. Whether it would also collapse when trained on data generated by other AI models remains to be seen. And with AI increasingly tapping into images, sounds, and videos, it’s still unclear if the same phenomenon appears in those models too.
But the results suggest there’s a “first-mover” advantage in AI. Companies that scraped the internet earlier—before it was polluted by AI-generated content—have the upper hand.
There’s no denying generative AI is changing the world. But the study suggests models can’t be sustained or grow over time without original output from human minds—even if it’s memes or grammatically-challenged comments. Model collapse is about more than a single company or country.
What’s needed now is community-wide coordination to mark AI-created data, and openly share the information, wrote the team. “Otherwise, it may become increasingly difficult to train newer versions of LLMs [large language models] without access to data that were crawled from the internet before the mass adoption of the technology or direct access to data generated by humans at scale.”
Image Credit: Kadumago / Wikimedia Commons
Kategorie: Transhumanismus
AI-Powered Weather and Climate Models Are Set to Change Forecasting
A new system for forecasting weather and predicting future climate uses artificial intelligence to achieve results comparable with the best existing models while using much less computer power, according to its creators.
In a paper published in Nature yesterday, a team of researchers from Google, MIT, Harvard, and the European Center for Medium-Range Weather Forecasts say their model offers enormous “computational savings” and can “enhance the large-scale physical simulations that are essential for understanding and predicting the Earth system.”
The NeuralGCM model is the latest in a steady stream of research models that use advances in machine learning to make weather and climate predictions faster and cheaper.
What Is NeuralGCM?The NeuralGCM model aims to combine the best features of traditional models with a machine-learning approach.
At its core, NeuralGCM is what’s called a “general circulation model.” It contains a mathematical description of the physical state of Earth’s atmosphere and solves complicated equations to predict what will happen in the future.
However, NeuralGCM also uses machine learning—a process of searching out patterns and regularities in vast troves of data—for some less well-understood physical processes, such as cloud formation. The hybrid approach makes sure the output of the machine learning modules will be consistent with the laws of physics.
The resulting model can then be used for making forecasts of weather days and weeks in advance, as well as looking months and years ahead for climate predictions.
The researchers compared NeuralGCM against other models using a standardized set of forecasting tests called WeatherBench 2. For three- and five-day forecasts, NeuralGCM did about as well as other machine-learning weather models such as Pangu and GraphCast. For longer-range forecasts, over 10 and 15 days, NeuralGCM was about as accurate as the best existing traditional models.
NeuralGCM was also quite successful in forecasting less-common weather phenomena, such as tropical cyclones and atmospheric rivers.
Why Machine Learning?Machine learning models are based on algorithms that learn patterns in the data fed to them and then use this learning to make predictions. Because climate and weather systems are highly complex, machine learning models require vast amounts of historical observations and satellite data for training.
The training process is very expensive and requires a lot of computer power. However, after a model is trained, using it to make predictions is fast and cheap. This is a large part of their appeal for weather forecasting.
The high cost of training and low cost of use is similar to other kinds of machine learning models. GPT-4, for example, reportedly took several months to train at a cost of more than $100 million, but can respond to a query in moments.
A comparison of how NeuralGCM compares with leading models (AMIP) and real data (ERA5) at capturing climate change between 1980 and 2020. Credit: Google Research
A weakness of machine learning models is that they often struggle in unfamiliar situations—or in this case, extreme or unprecedented weather conditions. To improve at this, a model needs to generalize, or extrapolate beyond the data it was trained on.
NeuralGCM appears to be better at this than other machine learning models because its physics-based core provides some grounding in reality. As Earth’s climate changes, unprecedented weather conditions will become more common, and we don’t know how well machine learning models will keep up.
Nobody is actually using machine learning-based weather models for day-to-day forecasting yet. However, it is a very active area of research—and one way or another, we can be confident that the forecasts of the future will involve machine learning.
This article is republished from The Conversation under a Creative Commons license. Read the original article.
Image Credit: Kochov et al. / Nature
Kategorie: Transhumanismus
Scientists Say They Extended Mice’s Lifespans 25% With an Antibody Drug
Age catches up with us all. Eyes struggle to focus. Muscles wither away. Memory dwindles. The risk of high blood pressure, diabetes, and other age-related diseases skyrockets.
A myriad of anti-aging therapies are in the works, and a new one just joined the fray. In mice, blocking a protein that promotes inflammation in middle age increased metabolism, lowered muscle wasting and frailty, and reduced the chances of cancer.
Unlike most previous longevity studies that tracked the health of aging male mice, the study involved both sexes, and the therapy worked across the board.
Lovingly called “supermodel grannies” by the team, the elderly lady mice looked and behaved far younger than their age, with shiny coats of fur, less fatty tissue, and muscles rivaling those of much younger mice.
The treatment didn’t just boost healthy longevity, also known as healthspan—the number of years living without diseases—it also increased the mice’s lifespan by up 25 percent. The average life expectancy of people in the US is roughly 77.5 years. If the results translate from mice to people—and that’s a very big if—it could mean a bump to almost 97 years.
The protein, dubbed IL-11, has been in scientists’ crosshairs for decades. It promotes inflammation and causes lung and kidney scarring. It’s also been associated with various types of cancers and senescence. The likelihood of all these conditions increases as we age.
Among a slew of pro-aging proteins already discovered, IL-11 stands out as it could make a beeline for testing in humans. Blockers for IL-11 are already in the works for treating cancer and tissue scarring. Although clinical trials are still ongoing, early results show the drugs are relatively safe in humans.
“Previously proposed life-extending drugs and treatments have either had poor side-effect profiles, or don’t work in both sexes, or could extend life, but not healthy life, however this does not appear to be the case for IL-11,” said study author Dr. Stuart Cook in a press release. “These findings are very exciting.”
Strange CoincidenceIn 2017, Cook zeroed in on IL-11 as a treatment target for heart and kidney scarring, not longevity. Injecting IL-11 triggered the conditions, eventually leading to organ failure. Genetically deleting the protein protected against the diseases.
It’s easy to call IL-11 a villain. But the protein is an essential part of the immune system. Produced by the bone marrow, it’s necessary for embryo implantation. It also helps certain types of blood cells grow and mature, notably those that stop bleeding after a scrape.
With age, however, the protein tends to goes rogue. It sparks inflammation across the body, damaging cells and tissues and contributing to cancer, autoimmune disorders, and tissue scarring. A “hallmark of aging,” inflammation has long been targeted as a way to reduce age-related diseases. Although IL-11 is a known trigger for inflammation, it hasn’t been directly linked to aging.
Until now. The story is one of chance.
“This project started back in 2017 when a collaborator of ours sent us some tissue samples for another project,” said study author Anissa Widjaja in the press release. She was testing a method to accurately detect IL-11. Several samples of an old rat’s proteins were in the mix, and she realized that IL-11 levels were far higher in the samples than in those from younger mice.
“From the readings, we could clearly see that the levels of IL-11 increased with age, and that’s when we got really excited,” she said.
Longevity BlockerThe results spurred the team to shift their research focus to longevity. A series of tests confirmed IL-11 levels consistently rose in a variety of tissues—muscle, fat, and liver—in both male and female mice as they aged.
To see how IL-11 influences the body, the team next deleted the gene coding for IL-11 and compared mice without the protein to their normal peers. At two years old, considered elderly for mice, tissues in normal individuals were littered with genetic signatures suggesting senescence—when cells lose their function but are still alive. Often called “zombie cells,” they spew out a toxic mix of inflammatory molecules and harm their neighbors. Elderly mice without IL-11, however, had senescence genetic profiles similar to those of much younger mice.
Deleting IL-11 had other perks. Weight gain is common with age, but without IL-11, the mice maintained their slim shape and had lower levels of fat, greater lean muscle mass, and shiny, full coats of fur. It’s not just about looks. Cholesterol levels and markers for liver damage were far lower than in normal peers. Aged mice without IL-11 were also spared shaking tremors—otherwise common in elderly mice—and could flexibly adjust their metabolism depending on the quantity of food they ate.
The benefits also showed up in their genetic material. DNA is protected by telomeres—a sort of end cap on chromosomes—that dwindle in length with age. Ridding cells of IL-11 prevented telomeres from eroding away in the livers and muscles of the elderly mice.
Genetically deleting IL-11 is a stretch for clinical use in humans. The team next turned to a more feasible alternative: An antibody shot. Antibodies can grab onto a target, in this case IL-11, and prevent it from functioning.
Beginning at 75 weeks, roughly the equivalent of 55 human years, the mice received an antibody shot every month for 25 weeks—over half a year. Similar antibodies are already being tested in clinical trials.
The health benefits in these mice matched those in mice without IL-11. Their weight and fat decreased, and they could better handle sugar. They also fought off signs of frailty as they aged, experiencing minimal tremors and problems with gait and maintaining higher metabolisms. Rather than wasting away, their muscles were even stronger than at the beginning of the study.
The treatment didn’t just increase healthspan. Monthly injections of the IL-11 antibody until natural death also increased lifespan in both male and female mice by up to 25 percent.
“These findings are very exciting. The treated mice had fewer cancers and were free from the usual signs of aging and frailty… In other words, the old mice receiving anti-IL-11 were healthier,” said Cook.
Although IL-11 antibody drugs are already in clinical trials, translating these results to humans could face hurdles. Mice have a relatively short lifespan. A longevity trial in humans would be long and very expensive. The treated mice were also contained in a lab setting, whereas in the real world we roam around and have differing lifestyles—diet, exercise, drinking, smoking—that could confound results. Even if it works in humans, a shot every month beginning in middle age would likely rack up a hefty bill, providing health and life extension only to those who could afford it.
To Cook, rather than focusing on extending longevity per se, tackling a specific age-related problem, such as tissue scarring or losing muscles is a better alternative for now.
“While these findings are only in mice, it raises the tantalizing possibility that the drugs could have a similar effect in elderly humans. Anti-IL-11 treatments are currently in human clinical trials for other conditions, potentially providing exciting opportunities to study its effects in aging humans in the future,” he said.
Image Credit: MRC LMS, Duke-NUS Medical School
Kategorie: Transhumanismus
When spear phishing met mass phishing
Introduction
Bulk phishing email campaigns tend to target large audiences. They use catch-all wordings and simplistic formatting, and typos are not uncommon. Targeted attacks take greater effort, with attackers sending personalized messages that include personal details and might look more like something you’d get from your employer or a customer. Adopting that approach on a larger scale is a pricey endeavor. Yet, certain elements of spear phishing recently started to be used in regular mass phishing campaigns. This story looks at some real-life examples that illustrate the trend.
Spear phishing vs. mass phishingSpear phishing is a type of attack that targets a specific individual or small group. Phishing emails like that feature information about the victim, and they tend to copy, both textually and visually, the style used by the company that they pretend to be from. They’re not easy to see for what they are: the attackers avoid errors in technical headers and don’t use email tools that could get them blocked, such as open email relays or bulletproof hosting services included in blocklists, such as DNS-based blocklist (DNSBL).
By contrast, mass phishing campaigns are designed for a large number of recipients: the messages are generalized in nature, they are not addressed to a specific user and do not feature the name of the addressee’s company or any other personalized details. Typos, mistakes and poor design are all common. Today’s AI-powered editing tools help attackers write better, but the text and formatting found in bulk email is still occasionally substandard. There is no structure to who gets targeted: attackers run their campaigns across entire databases of email addresses available to them. It’s a one-size-fits-all message inside: corporate discounts, security alerts from popular services, issues with signing in and the like.
Attacks evolving: real-life examplesUnlike other types of email phishing, spear phishing was never a tool for mass attacks. However, as we researched user requests in late 2023, we spotted an anomaly in how detections were distributed statistically. A lot of the emails that we found were impossible to pigeonhole as either targeted or mass-oriented. They boasted a quality design, personalized details of the targeted company and styling that imitated HR notifications. Still the campaigns were too aggressive and sent on too mass a scale to qualify as spear phishing.
An HR phishing email message: the body references the company, the recipient is addressed by their name, and the content is specialized enough so as to feel normal to a vigilant user
Besides, the message linked to a typical fake Outlook sign-in form. The form was not customized to reflect the target company’s style – a sure sign of bulk phishing.
The phishing sign-in form that opened when the user clicked the link in the email
Another similar campaign uses so-called ghost spoofing, a type of spoofing that adds a real corporate email address to the sender’s name, but does not hide or modify the actual domain. The technique sees increasing use in targeted attacks, but it’s overkill for mass phishing.
An HR phishing email message that uses ghost spoofing: the sender’s name contains the HR team’s email address, lending an air of authenticity to the email
As in the previous example, the phishing link in the email doesn’t have any unique features that a spear phishing link would. The sign-in form that opens contains no personalized details, while the design looks exactly like many other forms of this kind. It is hosted on an IPFS service like those often used in mass attacks.
The IPFS phishing sign-in form
StatisticsThe number of mixed phishing emails, March-May, 2024 (download)
We detected a substantial increase in the number of those mixed attacks in March through May 2024. First and foremost, this is a sign that tools used by attackers are growing in complexity and sophistication. Today’s technology lowers the cost of launching personalized attacks at scale. AI-powered tools can style the email body as an official HR request, fix typos and create a clean design. We have also observed a proliferation of third-party spear phishing services. This calls for increased vigilance on the part of users and more robust corporate security infrastructure.
TakeawaysAttackers are increasingly adopting spear phishing methods and technology in their bulk phishing campaigns: emails they send are growing more personalized, and the range of their spoofing technologies and tactics is expanding. These are still mass email campaigns and as such present a potential threat. This calls for safeguards that keep up with the pace of advances in technology while combining sets of methods and services to combat each type of phishing.
To fend off email attacks that combine spear and mass phishing elements:
- Pay attention to the sender’s address and the actual email domain: in an official corporate email, these must match.
- If something smells phishy, ask the sender to clarify, but don’t just reply to the email: use a different communication channel.
- Hold regular awareness sessions for your team to educate them about email phishing.
- Use advanced security solutions that incorporate anti-spam filtering and protection.
Kategorie: Hacking & Security, Viry a Červi
Developing and prioritizing a detection engineering backlog based on MITRE ATT&CK
Detection is a traditional type of cybersecurity control, along with blocking, adjustment, administrative and other controls. Whereas before 2015 teams asked themselves what it was that they were supposed to detect, as MITRE ATT&CK evolved, SOCs were presented with practically unlimited space for ideas on creating detection scenarios.
With the number of scenarios becoming virtually unlimited, another question inevitably arises: “What do we detect first?” This and the fact that SOC teams forever play the long game, having to respond with limited resources to a changing threat landscape, evolving technology and increasingly sophisticated malicious actors, makes managing efforts to develop detection logic an integral part of any modern SOC’s activities.
The problem at hand is easy to put into practical terms: the bulk of the work done by any modern SOC – with the exception of certain specialized SOC types – is detecting, and responding to, information security incidents. Detection is directly associated with preparation of certain algorithms, such as signatures, hard-coded logic, statistical anomalies, machine learning and others, that help to automate the process. The preparation consists of at least two processes: managing detection scenarios and developing detection logic. These cover the life cycle, stages of development, testing methods, go-live, standardization, and so on. These processes, like any others, require certain inputs: an idea that describes the expected outcome at least in abstract terms.
This is where the first challenges arise: thanks to MITRE ATT&CK, there are too many ideas. The number of described techniques currently exceeds 200, and most are broken down into several sub-techniques – MITRE T1098 Account Manipulation, for one, contains six sub-techniques – while SOC’s resources are limited. Besides, SOC teams likely do not have access to every possible source of data for generating detection logic, and some of those they do have access to are not integrated with the SIEM system. Some sources can help with generating only very narrowly specialized detection logic, whereas others can be used to cover most of the MITRE ATT&CK matrix. Finally, certain cases require activating extra audit settings or adding selective anti-spam filtering. Besides, not all techniques are the same: some are used in most attacks, whereas others are fairly unique and will never be seen by a particular SOC team. Thus, setting priorities is both about defining a subset of techniques that can be detected with available data and about ranking the techniques within that subset to arrive at an optimized list of detection scenarios that enables detection control considering available resources and in the original spirit of MITRE ATT&CK: discovering only some of the malicious actor’s atomic actions is enough for detecting the attack.
A slight detour. Before proceeding to specific prioritization techniques, it is worth mentioning that this article looks at options based on tools built around the MITRE ATT&CK matrix. It assesses threat relevance in general, not in relation to specific organizations or business processes. Recommendations in this article can be used as a starting point for prioritizing detection scenarios. A more mature approach must include an assessment of a landscape that consists of security threats relevant to your particular organization, an allowance for your own threat model, an up-to-date risk register, and automation and manual development capabilities. All of this requires an in-depth review, as well as liaison between various processes and roles inside your SOC. We offer more detailed maturity recommendations as part of our SOC consulting services.
MITRE Data SourcesOptimized prioritization of the backlog as it applies to the current status of monitoring can be broken down into the following stages:
- Defining available data sources and how well they are connected;
- Identifying relevant MITRE ATT&CK techniques and sub-techniques;
- Finding an optimal relation between source status and technique relevance;
- Setting priorities.
A key consideration in implementing this sequence of steps is the possibility of linking information that the SOC receives from data sources to a specific technique that can be detected with that information. In 2021, MITRE completed its ATT&CK Data Sources project, its result being a methodology for describing a data object that can be used for detecting a specific technique. The key elements for describing data objects are:
- Data Source: an easily recognizable name that defines the data object (Active Directory, application log, driver, file, process and so on);
- Data Components: possible data object actions, statuses and parameters. For example, for a file data object, data components are file created, file deleted, file modified, file accessed, file metadata, and so on.
MITRE Data Sources
Virtually every technique in the MITRE ATT&CK matrix currently contains a Detection section that lists data objects and relevant data components that can be used for creating detection logic. A total of 41 data objects have been defined at the time of publishing this article.
MITRE most relevant data componentsThe column on the far right in the image above (Event Logs) illustrates the possibilities of expanding the methodology to cover specific events received from real data sources. Creating a mapping like this is not one of the ATT&CK Data Sources project goals. This Event Logs example is rather intended as an illustration. On the whole, each specific SOC is expected to independently define a list of events relevant to its sources, a fairly time-consuming task.
To optimize your approach to prioritization, you can start by isolating the most frequent data components that feature in most MITRE ATT&CK techniques.
The graph below presents the up-to-date top 10 data components for MITRE ATT&CK matrix version 15.1, the latest at the time of writing this.
The most relevant data components (download)
For these data components, you can define custom sources for the most results. The following will be of help:
- Expert knowledge and overall logic. Data objects and data components are typically informative enough for the engineer or analyst working with data sources to form an initial judgment on the specific sources that can be used.
- Validation directly inside the event collection system. The engineer or analyst can review available sources and match events with data objects and data components.
- Publicly available resources on the internet, such as Sensor Mappings to ATT&CK, a project by the Center for Threat-Informed Defense, or this excellent resource on Windows events: UltimateWindowsSecurity.
That said, most sources are fairly generic and typically connected when a monitoring system is implemented. In other words, the mapping can be reduced to selecting those sources which are connected in the corporate infrastructure or easy to connect.
The result is an unranked list of integrated data sources that can be used for developing detection logic, such as:
- For Command Execution: OS logs, EDR, networked device administration logs and so on;
- For Process Creation: OS logs, EDR;
- For Network Traffic Content: WAF, proxy, DNS, VPN and so on;
- For File Modification: DLP, EDR, OS logs and so on.
However, this list is not sufficient for prioritization. You also need to consider other criteria, such as:
- The quality of source integration. Two identical data sources may be integrated with the infrastructure differently, with different logging settings, one source being located only in one network segment, and so on.
- Usefulness of MITRE ATT&CK techniques. Not all techniques are equally useful in terms of optimization. Some techniques are more specialized and aimed at detecting rare attacker actions.
- Detection of the same techniques with several different data sources (simultaneously). The more options for detecting a technique have been configured, the higher the likelihood that it will be discovered.
- Data component variability. A selected data source may be useful for detecting not only those techniques associated with the top 10 data components but others as well. For example, an OS log can be used for detecting both Process Creation components and User Account Authentication components, a type not mentioned on the graph.
Now that we have an initial list of data sources available for creating detection logic, we can proceed to scoring and prioritization. You can automate some of this work with the help of DeTT&CT, a tool created by developers unaffiliated with MITRE to help SOCs with using MITRE ATT&CK for scoring and comparing the quality of data sources, coverage and detection scope according to MITRE ATT&CK techniques. The tool is available under the GPL-3.0 license.
DETT&CT supports an expanded list of data sources as compared to the MITRE model. This list is implemented by design and you do not need to redefine the MITRE matrix itself. The expanded model includes several data components, which are parts of MITRE’s Network Traffic component, such as Web, Email, Internal DNS, and DHCP.
You can install DETT&CT with the help of two commands: git clone and pip install -r. This gives you access to DETT&CT Editor: a web interface for describing data sources, and DETT&CT CLI for automated analysis of prepared input data that can help with prioritizing detection logic and more.
The first step in identifying relevant data sources is describing these. Go to Data Sources in DETT&CT Editor, click New file and fill out the fields:
- Domain: the version of the MITRE ATT&CK matrix to use (enterprise, mobile or ICS).
- This field is not used in analytics; it is intended for distinguishing between files with the description of sources.
- Systems: selection of platforms that any given data source belongs to. This helps to both separate platforms, such as Windows and Linux, and specify several platforms within one system. Going forward, keep in mind that a data source is assigned to a system, not a platform. In other words, if a source collects data from both Windows and Linux, you can leave one system with two platforms, but if one source collects data from Windows only, and another, from Linux only, you need to create two systems: one for Windows and one for Linux.
After filling out the general sections, you can proceed to analyzing data sources and mapping to the MITRE Data Sources. Click Add Data Source for each MITRE data object and fill out the relevant fields. Follow the link above for a detailed description of all fields and example content on the project page. We will focus on the most interesting field: Data quality. It describes the quality of data source integration as determined according to five criteria:
- Device completeness. Defines infrastructure coverage by the source, such as various versions of Windows or subnet segments, and so on.
- Data field completeness. Defines the completeness of data in events from the source. For example, information about Process Creation may be considered incomplete if we see that a process was created, but not the details of the parent process, or for Command Execution, we see the command but not the arguments, and so on.
- Defines the presence of a delay between the event happening and being added to a SIEM system or another detection system.
- Defines the extent to which the names of the data fields in an event from this source are consistent with standard naming.
- Compares the period for which data from the source is available for detection with the data retention policy defined for the source. For instance, data from a certain source is available for one month, whereas the policy or regulatory requirements define the retention period as one year.
A detailed description of the scoring system for filling out this field is available in the project description.
It is worth mentioning that at this step, you can describe more than just the top 10 data components that cover the majority of the MITRE ATT&CK techniques. Some sources can provide extra information: in addition to Process Creation, Windows Security Event Log provides data for User Account Authentication. This extension will help to analyze the matrix without limitations in the future.
After describing all the sources on the list defined earlier, you can proceed to analyze these with reference to the MITRE ATT&CK matrix.
The first and most trivial analytical report identifies the MITRE ATT&CK techniques that can be discovered with available data sources one way or another. This report is generated with the help of a configuration file with a description of data sources and DETT&CT CLI, which outputs a JSON file with MITRE ATT&CK technique coverage. You can use the following command for this:
python dettect.py ds -fd <data-source-yaml-dir>/<data-sources-file.yaml> -lThe resulting JSON is ready to be used with the MITRE ATT&CK matrix visualization tool, MITRE ATT&CK Navigator. See below for an example.
MITRE ATT&CK coverage with available data sources
This gives a literal answer to the question of what techniques the SOC can discover with the set of data sources that it has. The numbers in the bottom right-hand corner of some of the cells reflect sub-technique coverage by the data sources, and the colors, how many different sources can be used to detect the technique. The darker the color, the greater the number of sources.
DETT&CT CLI can also generate an XLSX file that you can conveniently use as the integration of existing sources evolves, a parallel task that is part of the data source management process. You can use the following command to generate the file:
python dettect.py ds -fd <data-source-yaml-dir>/<data-sources-file.yaml> -eThe next analytical report we are interested in assesses the SOC’s capabilities in terms of detecting MITRE ATT&CK techniques and sub-techniques while considering the scoring of integrated source quality as done previously. You can generate the report by running the following command:
python dettect.py ds -fd <data-source-yaml-dir>/<data-sources-file.yaml> --yamlThis generates a DETT&CT configuration file that both contains matrix coverage information and considers the quality of the data sources, providing a deeper insight into the level of visibility for each technique. The report can help to identify the techniques for which the SOC in its current shape can achieve the best results in terms of completeness of detection and coverage of the infrastructure.
This information too can be visualized with MITRE ATT&CK Navigator. You can use the following DETT&CT CLI command for this:
python dettect.py v -ft output/<techniques-administration-file.yaml> -lSee below for an example.
MITRE ATT&CK coverage with available sources considering their quality
For each technique, the score is calculated as an average of all relevant data source scores. For each data source, it is calculated from specific parameters. The following parameters have increased weight:
- Device completeness;
- Data field completeness;
- Retention.
To set up the scoring model, you need to modify the project source code.
It is worth mentioning that the scoring system presented by the developers of DETT&CT tends to be fairly subjective in some cases, for example:
- You may have one data source out of the three mentioned in connection with the specific technique. However, in some cases, one data source may not be enough even to detect the technique on a minimal level.
- In other cases, the reverse may be true, with one data source giving exhaustive information for complete detection of the technique.
- Detection may be based on a data source that is not currently mentioned in the MITRE ATT&CK Data Sources or Detections for that particular technique.
In these cases, the DETT&CT configuration file techniques-administration-file.yaml can be adjusted manually.
Now that the available data sources and the quality of their integration have been associated with the MITRE ATT&CK matrix, the last step is ranking the available techniques. You can use the Procedure Examples section in the matrix, which defines the groups that use a specific technique or sub-technique in their attacks. You can use the following DETT&CT command to run the operation for the entire MITRE ATT&CK matrix:
python dettect.py gIn the interests of prioritization, we can merge the two datasets (technique feasibility considering available data sources and their quality, and the most frequently used MITRE ATT&CK techniques):
python dettect.py g -p PLATFORM -o output/<techniques-administration- file.yaml> -t visibilityThe result is a JSON file containing techniques that the SOC can work with and their description, which includes the following:
- Detection ability scoring;
- Known attack frequency scoring.
See the image below for an example.
Technique frequency and detection ability
As you can see in the image, some of the techniques are colored shades of red, which means they have been used in attacks (according to MITRE), but the SOC has no ability to detect them. Other techniques are colored shades of blue, which means the SOC can detect them, but MITRE has no data on these techniques having been used in any attacks. Finally, the techniques colored shades of orange are those which groups known to MITRE have used and the SOC has the ability to detect.
It is worth mentioning that groups, attacks and software used in attacks, which are linked to a specific technique, represent retrospective data collected throughout the period that the matrix has existed. In some cases, this may result in increased priority for techniques that were relevant for attacks, say, from 2015 through 2020, which is not really relevant for 2024.
However, isolating a subset of techniques ever used in attacks produces more meaningful results than simple enumeration. You can further rank the resulting subset in the following ways:
- By using the MITRE ATT&CK matrix in the form of an Excel table. Each object (Software, Campaigns, Groups) contains the property Created (date when the object was created) that you can rely on when isolating the most relevant objects and then use the resulting list of relevant objects to generate an overlap as described above:
python dettect.py g -g sample-data/groups.yaml -p PLATFORM -o output/<techniques-administration-file.yaml> -t visibility - By using the TOP ATT&CK TECHNIQUES project created by MITRE Engenuity.
TOP ATT&CK TECHNIQUES was aimed at developing a tool for ranking MITRE ATT&CK techniques and accepts similar inputs to DETT&CT. The tool produces a definition of 10 most relevant MITRE ATT&CK techniques for detecting with available monitoring capabilities in various areas of the corporate infrastructure: network communications, processes, the file system, cloud-based solutions and hardware. The project also considers the following criteria:
- Choke Points, or specialized techniques where other techniques converge or diverge. Examples of these include T1047 WMI, as it helps to implement a number of other WMI techniques, or T1059 Command and Scripting Interpreter, as many other techniques rely on a command-line interface or other shells, such as PowerShell, Bash and others. Detecting this technique will likely lead to discovering a broad spectrum of attacks.
- Prevalence: technique frequency over time.
MITRE ATT&CK technique ranking methodology in TOP ATT&CK TECHNIQUES
Note, however, that the project is based on MITRE ATT&CK v.10 and is not supported.
Finalizing prioritiesBy completing the steps above, the SOC team obtains a subset of MITRE ATT&CK techniques that feature to this or that extent in known attacks and can be detected with available data sources, with an allowance for the way these are configured in the infrastructure. Unfortunately, DETT&CT does not offer any way of creating a convenient XLSX file with an overlap between techniques used in attacks and those that the SOC can detect. However, we have a JSON file that can be used to generate the overlap with the help of MITRE ATT&CK Navigator. So, all you need to do for prioritization is to parse the JSON, say, with the help of Python. The final prioritization conditions may be as follows:
- Priority 1 (critical): Visibility_score >= 3 and Attacker_score >= 75. From an applied perspective, this isolates MITRE ATT&CK techniques that most frequently feature in attacks and that the SOC requires minimal or no preparation to detect.
- Priority 2 (high): (Visibility_score < 3 and Visibility_score >= 1) and Attacker_score >= 75. These are MITRE ATT&CK techniques that most frequently feature in attacks and that the SOC is capable of detecting. However, some work on logging may be required, or monitoring coverage may not be good enough.
- Priority 3 (medium): Visibility_score >= 3 and Attacker_score < 75. These are MITRE ATT&CK techniques with medium to low frequency that the SOC requires minimal or no preparation to detect.
- Priority 4 (low): (Visibility_score < 3 and Visibility_score >= 1) and Attacker_score < 75. These are all other MITRE ATT&CK techniques that feature in attacks and the SOC has the capability to detect.
As a result, the SOC obtains a list of MITRE ATT&CK techniques ranked into four groups and mapped to its capabilities and global statistics on malicious actors’ actions in attacks. The list is optimized in terms of the cost to write detection logic and can be used as a prioritized development backlog.
Prioritization extension and parallel tasksIn conclusion, we would like to highlight the key assumptions and recommendations for using the suggested prioritization method.
- As mentioned above, it is not fully appropriate to use the MITRE ATT&CK statistics on the frequency of techniques in attacks. For more mature prioritization, the SOC team must rely on relevant threat data. This requires defining a threat landscape based on analysis of threat data, mapping applicable threats to specific devices and systems, and isolating the most relevant techniques that may be used against a specific system in the specific corporate environment. An approach like this calls for in-depth analysis of all SOC activities and links between processes. Thus, when generating a scenario library for a customer as part of our consulting services, we leverage Kaspersky Threat Intelligence data on threats relevant to the organization, Managed Detection and Response statistics on detected incidents, and information about techniques that we obtained while investigating real-life incidents and analyzing digital evidence as part of Incident Response service.
- The suggested method relies on SOC capabilities and essential MITRE ATT&CK analytics. That said, the method is optimized for effort reduction and helps to start developing relevant detection logic immediately. This makes it suitable for small-scale SOCs that consist of a SIEM administrator or analyst. In addition to this, the SOC builds what is essentially a detection functionality roadmap, which can be used for demonstrating the process, defining KPIs and justifying a need for expanding the team.
Lastly, we introduce several points regarding the possibilities for improving the approach described herein and parallel tasks that can be done with tools described in this article.
You can use the following to further improve the prioritization process.
- Grouping by detection. On a basic level, there are two groups: network detection or detection on a device. Considering the characteristics of the infrastructure and data sources in creating detection logic for different groups helps to avoid a bias and ensure a more complete coverage of the infrastructure.
- Grouping by attack stage. Detection at the stage of Initial Access requires more effort, but it leaves more time to respond than detection at the Exfiltration stage.
- Criticality coefficient. Certain techniques, such as all those associated with vulnerability exploitation or suspicious PowerShell commands, cannot be fully covered. If this is the case, the criticality level can be used as an additional criterion.
- Granular approach when describing source quality. As mentioned earlier, DETT&CT helps with creating quality descriptions of available data sources, but it lacks exception functionality. Sometimes, a source is not required for the entire infrastructure, or there is more than one data source providing information for similar systems. In that case, a more granular approach that relies on specific systems, subnets or devices can help to make the assessment more relevant. However, an approach like that calls for liaison with internal teams responsible for configuration changes and device inventory, who will have to at least provide information about the business criticality of assets.
Besides improving the prioritization method, the tools suggested can be used for completing a number of parallel tasks that help the SOC to evolve.
- Expanding the list of sources. As shown above, the coverage of the MITRE ATT&CK matrix requires diverse data sources. By mapping existing sources to techniques, you can identify missing logs and create a roadmap for connecting or introducing these sources.
- Improving the quality of sources. Scoring the quality of data sources can help create a roadmap for improving existing sources, for example in terms of infrastructure coverage, normalization or data retention.
- Detection tracking. DETT&CT offers, among other things, a detection logic scoring feature, which you can use to build a detection scenario revision process.
Kategorie: Hacking & Security, Viry a Červi
CloudSorcerer – A new APT targeting Russian government entities
In May 2024, we discovered a new advanced persistent threat (APT) targeting Russian government entities that we dubbed CloudSorcerer. It’s a sophisticated cyberespionage tool used for stealth monitoring, data collection, and exfiltration via Microsoft Graph, Yandex Cloud, and Dropbox cloud infrastructure. The malware leverages cloud resources as its command and control (C2) servers, accessing them through APIs using authentication tokens. Additionally, CloudSorcerer uses GitHub as its initial C2 server.
CloudSorcerer’s modus operandi is reminiscent of the CloudWizard APT that we reported on in 2023. However, the malware code is completely different. We presume that CloudSorcerer is a new actor that has adopted a similar method of interacting with public cloud services.
Our findings in a nutshell:
- CloudSorcerer APT uses public cloud services as its main C2s
- The malware interacts with the C2 using special commands and decodes them using a hardcoded charcode table.
- The actor uses Microsoft COM object interfaces to perform malicious operations.
- CloudSorcerer acts as separate modules (communication module, data collection module) depending on which process it’s running, but executes from a single executable.
The malware is executed manually by the attacker on an already infected machine. It is initially a single Portable Executable (PE) binary written in C. Its functionality varies depending on the process in which it is executed. Upon execution, the malware calls the GetModuleFileNameA function to determine the name of the process it is running in. It then compares this process name with a set of hardcoded strings: browser, mspaint.exe, and msiexec.exe. Depending on the detected process name, the malware activates different functions:
- If the process name is mspaint.exe, CloudSorcerer functions as a backdoor module, and performs activities such as data collection and code execution.
- If the process name is msiexec.exe, the CloudSorcerer malware initiates its C2 communication module.
- Lastly, if the process name contains the string “browser” or does not match any of the specified names, the malware attempts to inject shellcode into either the msiexec.exe, mspaint.exe, or explorer.exe processes before terminating the initial process.
The shellcode used by CloudSorcerer for initial process migration shows fairly standard functionality:
- Parse Process Environment Block (PEB) to identify offsets to required Windows core DLLs;
- Identify required Windows APIs by hashes using ROR14 algorithm;
- Map CloudSorcerer code into the memory of one of the targeted processes and run it in a separate thread.
All data exchange between modules is organized through Windows pipes, a mechanism for inter-process communication (IPC) that allows data to be transferred between processes.
CloudSorcerer backdoor moduleThe backdoor module begins by collecting various system information about the victim machine, running in a separate thread. The malware collects:
- Computer name;
- User name;
- Windows subversion information;
- System uptime.
All the collected data is stored in a specially created structure. Once the information gathering is complete, the data is written to the named pipe \\.\PIPE\[1428] connected to the C2 module process. It is important to note that all data exchange is organized using well-defined structures with different purposes, such as backdoor command structures and information gathering structures.
Next, the malware attempts to read data from the pipe \\.\PIPE\[1428]. If successful, it parses the incoming data into the COMMAND structure and reads a single byte from it, which represents a COMMAND_ID.
Main backdoor functionality
Depending on the COMMAND_ID, the malware executes one of the following actions:
- 0x1 – Collect information about hard drives in the system, including logical drive names, capacity, and free space.
- 0x2 – Collect information about files and folders, such as name, size, and type.
- 0x3 – Execute shell commands using the ShellExecuteExW API.
- 0x4 – Copy, move, rename, or delete files.
- 0x5 – Read data from any file.
- 0x6 – Create and write data to any file.
- 0x8 – Receive a shellcode from the pipe and inject it into any process by allocating memory and creating a new thread in a remote process.
- 0x9 – Receive a PE file, create a section and map it into the remote process.
- 0x7 – Run additional advanced functionality.
When the malware receives a 0x7 COMMAND_ID, it runs one of the additional tasks described below:
Command ID Operation Description 0x2307 Create process Creates any process using COM interfaces, used for running downloaded binaries. 0x2407 Create process as dedicated user Creates any process under dedicated username. 0x2507 Create process with pipe Creates any process with support of inter-process communication to exchange data with the created process. 0x3007 Clear DNS cache Clears the DNS cache. 0x2207 Delete task Deletes any Windows task using COM object interfaces. 0x1E07 Open service Opens a Windows service and reads its status. 0x1F07 Create new task Creates a new Windows task and sets up a trigger for execution using COM objects. 0x2007 Get tasks Gets the list of all the Windows tasks using COM object interface. 0x2107 Stop task Stops any task using COM object interface. 0x1D07 Get services Gets the list of all Windows services. 0x1907 Delete value from reg Deletes any value from any Windows registry key selected by the actor. 0x1A07 Create service Creates a new Windows service. 0x1B07 Change service Modifies any Windows service configuration. 0x1807 Delete reg key Deletes any Windows registry key. 0x1407 Get TCP/UDP update table Gets information from Windows TCP/UDP update table. 0x1507 Collect processes Collects all running processes. 0x1607 Set reg key value Modifies any Windows registry key. 0x1707 Enumerate reg key Enumerates Windows registry keys. 0x1307 Enumerate shares Enumerates Windows net shares. 0x1007 Set net user info Sets information about a user account on a Windows network using NetUserSetInfo. It allows administrators to modify user account properties on a local or remote machine. 0x1107 Get net members Gets a member of the local network group. 0x1207 Add member Adds a user to the local network group. 0xE07 Get net user info Collects information about a network user. 0xB07 Enumerate net users Enumerates network users. 0xC07 Add net user Adds a new network user. 0xD07 Delete user Deletes a network user. 0x907 Cancel connection Cancels an existing network connection. This function allows for the disconnection of network resources, such as shared directories. 0x507 File operations Copies, moves, or deletes any file. 0x607 Get net info Collects information about the network and interfaces. 0x707 Enumerate connections Enumerates all network connections. 0x807 Map network Maps remote network drive. 0x407 Read file Reads any file as text strings. 0x107 Enumerate RDP Enumerates all RDP sessions. 0x207 Run WMI Runs any WMI query using COM object interfaces. 0x307 Get files Creates list of files and folders.All the collected information or results of performed tasks are added to a specially created structure and sent to the C2 module process via a named pipe.
C2 moduleThe C2 module starts by creating a new Windows pipe named \\.\PIPE\[1428]. Next, it configures the connection to the initial C2 server by providing the necessary arguments to a sequence of Windows API functions responsible for internet connections:
- InternetCrackUrlA;
- InternetSetOptionA;
- InternetOpenA;
- InternetConnectA;
- HttpOpenRequestA;
- HttpSendRequestA
The malware sets the request type (“GET”), configures proxy information, sets up hardcoded headers, and provides the C2 URL.
Setting up internet connection
The malware then connects to the initial C2 server, which is a GitHub page located at https://github[.]com/alinaegorovaMygit. The malware reads the entire web page into a memory buffer using the InternetReadFile call.
The GitHub repository contains forks of three public projects that have not been modified or updated. Their purpose is merely to make the GitHub page appear legitimate and active. However, the author section of the GitHub page displays an interesting string:
Hex string in the author section
We found data that looks like a hex string that starts and ends with the same byte pattern – “CDOY”. After the malware downloads the entire GitHub HTML page, it begins parsing it, searching specifically for the character sequence “CDOY”. When it finds it, it copies all the characters up to the second delimiter “CDOY” and then stores them in a memory buffer. Next, the malware parses these characters, converting them from string values to hex values. It then decodes the string using a hardcoded charcode substitution table – each byte from the parsed string acts as an index in the charcode table, pointing to a substitutable byte, thus forming a new hex byte array.
Decoding algorithm
Charcode table
Alternatively, instead of connecting to GitHub, CloudSorcerer also tries to get the same data from hxxps://my.mail[.]ru/, which is a Russian cloud-based photo hosting server. The name of the photo album contains the same hex string.
The first decoded byte of the hex string is a magic number that tells the malware which cloud service to use. For example, if the byte is “1”, the malware uses Microsoft Graph cloud; if it is “0”, the malware uses Yandex cloud. The subsequent bytes form a string of a bearer token that is used for authentication with the cloud’s API.
Depending on the magic number, the malware creates a structure and sets an offset to a virtual function table that contains a subset of functions to interact with the selected cloud service.
Different virtual tables for Yandex and Microsoft
Next, the malware connects to the cloud API by:
- Setting up the initial connection using InternetOpenA and InternetConnectA;
- Setting up all the required headers and the authorization token received from the GitHub page;
- Configuring the API paths in the request;
- Sending the request using HttpSendRequestExA and checking for response errors;
- Reading data from the cloud using InternetReadFile.
The malware then creates two separate threads – one responsible for receiving data from the Windows pipe and another responsible for sending data to it. These threads facilitate asynchronous data exchange between the C2 and backdoor modules.
Finally, the C2 module interacts with the cloud services by reading data, receiving encoded commands, decoding them using the character code table, and sending them via the named pipe to the backdoor module. Conversely, it receives the command execution results or exfiltrated data from the backdoor module and writes them to the cloud.
Infrastructure GitHub pageThe GitHub page was created on May 7, 2024, and two repositories were forked into it on the same day. On May 13, 2024, another repository was forked, and no further interactions with GitHub occurred. The forked repositories were left untouched. The name of the C2 repository, “Alina Egorova,” is a common Russian female name; however, the photo on the GitHub page is of a male and was copied from a public photo bank.
Mail.ru photo hostingThis page contains the same encoded string as the GitHub page. There is no information about when the album was created and published. The photo of the owner is the same as the picture from the photo bank.
Cloud infrastructure Service Main URL Initial path Yandex Cloud cloud-api.yandex.net /v1/disk/resources?path=/v1/disk/resources/download?path=
/v1/disk/resources/upload?path= Microsoft Graph graph.microsoft.com /v1.0/me/drive/root:/Mg/%s/%s:/content Dropbox content.dropboxapi.com /2/files/download
/2/files/upload Attribution
The use of cloud services is not new, and we reported an example of this in our overview of the CloudWizard APT (a campaign in the Ukrainian conflict with ties to Operation Groundbait and CommonMagic). However, the likelihood of attributing CloudSorcerer to the same actor is low, as the code and overall functionality of the malware are different. We therefore assume at this point that CloudSorcerer is a new actor that has adopted the technique of interacting with public cloud services.
VictimsGovernment organizations in the Russian Federation.
ConclusionsThe CloudSorcerer malware represents a sophisticated toolset targeting Russian government entities. Its use of cloud services such as Microsoft Graph, Yandex Cloud, and Dropbox for C2 infrastructure, along with GitHub for initial C2 communications, demonstrates a well-planned approach to cyberespionage. The malware’s ability to dynamically adapt its behavior based on the process it is running in, coupled with its use of complex inter-process communication through Windows pipes, further highlights its sophistication.
While there are similarities in modus operandi to the previously reported CloudWizard APT, the significant differences in code and functionality suggest that CloudSorcerer is likely a new actor, possibly inspired by previous techniques but developing its own unique tools.
Indicators of CompromiseFile Hashes (malicious documents, Trojans, emails, decoys)
F701fc79578a12513c369d4e36c57224 CloudSorcererDomains and IPs
hxxps://github[.]com/alinaegorovaMygit CloudSorcerer C2 hxxps://my.mail[.]ru/yandex.ru/alinaegorova2154/photo/1 CloudSorcerer C2Yara Rules
rule apt_cloudsorcerer {
meta:
description = "Detects CloudSorcerer"
author = "Kaspersky"
copyright = "Kaspersky"
distribution = "DISTRIBUTION IS FORBIDDEN. DO NOT UPLOAD TO ANY MULTISCANNER OR SHARE ON ANY THREAT INTEL PLATFORM"
version = "1.0"
last_modified = "2024-06-06"
hash = "F701fc79578a12513c369d4e36c57224"
strings:
$str1 = "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
$str2 = "c:\\windows\\system32\\mspaint.exe"
$str3 = "C:\\Windows\\system32\\msiexec.exe"
$str4 = "\\\\.\\PIPE\\"
condition:
uint16(0) == 0x5A4D and
all of ($str*)
}
MITRE ATT&CK Mapping
Tactic
Technique
Technique Name
Execution
T1059.009
Command and Scripting Interpreter: Cloud API
T1559
Inter-Process Communication
T1053
Scheduled Task/Job
T1047
Windows Management Instrumentation
Persistence
T1543
Create or Modify System Process
T1053
Scheduled Task/Job
Defense Evasion
T1140
Deobfuscate/Decode Files or Information
T1112
Modify Registry
Discovery
T1083
File and Directory Discovery
T1046
Network Service Discovery
T1057
Process Discovery
T1012
Query Registry
T1082
System Information Discovery
Collection
T1005
Data from Local System
Command and Control
T1102
Web Service
T1568
Dynamic Resolution
Exfiltration
T1567
Exfiltration Over Web Service
T1537
Transfer Data to Cloud Account
Kategorie: Hacking & Security, Viry a Červi
pfSense, VLANy, proxy, … aneb začínáme krotit divočinu v domácí síti
Po čtrnácti dnech je tu závěrečný díl celé série o zabezpečení chytré domácnosti. Pokud tedy nechcete mít doma trojského koně v podobě čínské fotovoltaiky či jiných čínských chytrých zařízení, zde je rozuzlení celé problematiky. A vlastně, ono tohle řešení nabídne i daleko vyšší komfort než řada oficiálních řešení od výrobců!
Předem hlásím, že existuje hromada dalších způsobů, jak si zabezpečit domácí síť a jakým způsobem zajistit dostupnost chytrých zařízení z internetu. Já jsem to zrealizoval následovně.
VLANy – oddělené sítě a přesto provázanéDomácí síť mám rozdělenu do 4 VLAN s využítím IEEE 802.1Q a takhle to mám jak na úrovni bezdrátové (WiFi síť), tak i „drátové“ (ethernetové kabely CAT6). Poněkud úsměvná je ale realita, kdy mám po domě nataženo přes 300m ethernetového kabelu, v každé místnosti minimálně 2 zásuvky, za TV skříní hned 4 a přesto jsem ani tu televizi kabelem nepřipojil. 24-portový switch s podporou VLAN tak byla volba typu „kanónem na vrabce“. Zpět ale k VLAN. Mám nakonec tyto:
- IOT – zde mám všechna chytrá zařízení, včetně IP kamer, Shelly zařízení, Android TV + Home Assistant nainstalovaný na Raspberry Pi 3.
- SERVERS – zde mám NAS Synology a UniFi controller (v provozu na Raspberry Pi).
- PRIVATE – zde jsou zařízení jako stolní PC, notebook, mobilní telefony, tiskárna.
- GUEST – pro účely Guest WiFi. Vlastně velice podobné IOT, ale včetně izolace zařízení.
Home Assistant pro správu IOT zařízení by měl být z logiky věci spíše ve VLAN SERVERS, nicméně využívám toho, že takhle dokáže automaticky detekovat nová zařízení na stejném segmentu sítě (typicky když dokoupím další Shelly komponentu) a celá topologie sítě je o něco jednodušší.
pfSense – srdce celé infrastrukturyRoutování mezi VLANama obstarává pfSense, stejně jako funkci firewallu a dalších služeb. Nejprve jsem provozoval pfSense+ na oficiálním zařízení Netgate 1100. Jakmile si ale začnete s pfSense více hrát, zapínat inspekci provozu a další služby, velice rychle narazíte na limit RAM o velikosti 1 GB. Tudíž později došlo k výměně za výkonější stroj se 4 GB RAM – PC Engines s procesorem AMD GX-412TC-quad core. Bohužel AMD další vývoj těchto chipsetů ukončil, takže pokud to umře, do třetice to bude zase něco zcela jiného, avšak stále s pfSense.
pfSense má dlouhou historii. Je tu s námi od roku 2004, kdy se oddělil od jiné legendy – m0n0wall. V roce 2015 vznikla alternativa v podobě OPNsense. Vše běží na FreeBSD.VLANu IOT mám zcela odříznutou od internetu a ostatních VLAN. K dispozici je tam DHCP. Podle charakteru mají některá IOT zařízení IP adresu volně přiřazenu a jiné ji mají nastavenu „natvrdo“ (vůči MAC adrese + v nastavení IOT). Toto je typické pro IP kamery či jiná zařízení, kde by změna IP v čase mohla způsobit komplikace (tepelné čerpadlo, fotovoltaika – oboje kvůli TCP Modbus komunikaci). Jedinou povolenou komunikací směrem ven je DNS a NTP (kamery tak budou mít správný datum/čas). Na firewallu pak mám připraveny pravidla, která povolí základní set portů, pokud bych chtěl například aktualizovat firmware IOT zařízení či pustit k tepelnému čerpadlu vzdáleného technika. Standardně jako ale tato pravidla neaktivní.
Nejvíce benevolentní je pochopitelně nastavení VLAN SERVERS a PRIVATE. Z obou se lze dostat do všech ostatních.
Tři WiFi sítěDrtivou většinu IOT zařízení provozuju bezdrátově přes WiFi síť. WiFi řeším přes několik stropních „talířů“ značky Ubiquiti UniFi s POE napájením. VLANa IOT, PRIVATE a GUEST má své vlastní SSID. V okoli tak vidím 3 WiFi sítě. IOT WiFi jede jen na 2,4 GHz, ostatní pak na 2,4 i 5 GHz. Vím, že některá IOT zařízení mají problém s prvotní instalací, pokud Váš mobil jede na 5 GHz síti a má sloužit k spárování s IOT zařízením, jenž podporuje pouze 2,4 GHz. WiFi síť je pak řízena skrze UniFi Controller, který provozuju též na obstarožním Raspberry Pi 3.
Vedlejším efektem v případě Ubiquiti je například to, že Vám to samo vizualizuje infrastrukturu. Pozor na vyždímané baterie!Speciálně u bateriových zařízení (ideálně však všude) doporučuji v konfiguraci zakázat používání cloudové infrastruktury výrobce. On sice komunikaci zabrání firewall na pfSense, nicméně pokud necháte cloud povolený třeba v nastavení detektoru otevřených dvěří/oken „Shelly door window 2“, opakované neúspěšné pokusy o navázání komunikace s cloudem vedou k tomu, že baterii, která by měla v zařízení vydržet více než rok, vyždímáte v řádu týdnů! A že jsem těch náhradních baterií nakoupil, než jsem na to přišel Naopak v případě Shelly je doporučeno zapnout ColoT protokol a uvést IP adresu Home Assistant serveru.
To je asi vše k vnitřní části. Jak je ale realizována dostupnost IOT zařízení z internetu? Existuje opět spousta řešení, já se ale rozhodl pro následující.
Dostupnost chytré domácnosti z internetu po vlastní oseOd internetového poskytovatele mám zajištěnu statickou veřejnou IP adresu (i když stačí i promapování klíčových portů). K ní mám vytvořeny DNS záznamy typu A. Jeden pro přístup k NAS Synology (kde je i správa kamerového systému) a druhý k Home Assistant. Oba záznamy, resp. IP adresa mě dovede až k WAN portu firewallu pfSense.
Na pfSense běží služba pfBlockerNG, která využívá GeoIP pravidla a rovnou zahazuje komunikaci vedenou z jiných zemí, než ČR a SR a blacklistovaných IP adres. Intuitivně není problém přidávat další regiony. Pak je tam v provozu služba Snort, která detekuje různé anomálie v síťové komunikaci a též dokáže rozdávat ať už permanentní nebo dočasne „bany“ na veřejné IP adresy.
Reverzní proxy, HTTP SSL, ACME, Lets encrypt, Fail 2 ban, …Za tímhle je pak schovaná další služba, reverzní proxy HA Proxy, která legitimní požadavky z internetu na Home Assistant či Synology NAS směruje na správné „backendy“. Ať už se k NAS Synology či Home Assistantu připojujete z internetu skrze webový prohlížeč či mobilní aplikaci výrobce, technicky jde vždy o HTTP komunikaci. Nešifrovanou podobu na portu 80 mám pochopitelně zakázanou. Povolena je pouze šifrovaná varianta SSL, přičemž HA Proxy tuto komunikaci zaterminuje a dále ji podle hostname posílá lokálně již po HTTP na Synology či Home Assistant.
Validitu SSL certifikátů zařizuje další služba, jenž běží na pfSense – ACME. Využita je přitom autorita Lets Encrypt. Žádné výjimky na nedůvěryhodné servery tak není potřeba řešit. „Fail2Ban“, tedy blokování IP adres v případě, že se z ní někdo několikrát pokusí o neúspěšné přihlášení k systému, řeším až na cílových systémech Synology a Home Assistant. Aby to fungovalo korektně, je potřeba v HA Proxy povolit zasílání hlaviček X-Forwarded a brát je v potaz v nastavení Synology / Home Assistantu. V opačném případě zabanujete leda tak sami sebe, resp. vnitřní IP adresu pfSense, nikoliv skutečného viníka / útočníka.
ZávěrTohle je tak nějak v kostce řešení, které v domácnosti využívám. Znovu říkám, dalo by se to vyřešit úplně jinak, ale já jsem s tímhle maximálně spokojen. Vše mám v jedné aplikaci, která je rychlejší, lepší a stabilnější, než řada oficiálních řešení od výrobců. Home Assistant zároveň umožňuje realizovat automatizace, které by byly jinak nemyslitelné, drahé, nebo komplikované. Více o tom v předchozím díle. Nicméně zde je rekapitulace všech předchozích dílů:
Máte rádi trojské koně? Pořiďte si čínskou fotovoltaiku!
Rizika nevedou jen přes fotovoltaiku, stačí Vám „Powered by Tuya“ zařízení za pár stovek
Odříznutí internetu, přesun k Home Assistantu
A jak řešíte zabezpečení Vy? A nebo na to „prdíte“? Klidně pište do komentářů.
The post pfSense, VLANy, proxy, … aneb začínáme krotit divočinu v domácí síti appeared first on VIRY.CZ.
Kategorie: Viry a Červi
Odříznutí internetu, přesun k Home Assistantu
Třetí díl série o chytrých zařízeních (IOT – Internet of things) v domácnosti je již konkrétnější a ukazuje jednu z alternativních cest jejich použití, která je zcela odlišná od „mainstreamové“ cesty, kterou to zapojí drtivá většina ostatních uživatelů. V konečném důsledku může být právě tohle rozhodující faktor, díky kterému se můžete vyhnout případnému hackerskému útoku či výpadku cloudové infrastruktury výrobců IOT. Příjemným vedlejším efektem je navíc to, že často i stoupne komfort užití IOT zařízení a otevírají se další možnosti jejich spolupráce. Abych ale řekl celou pravdu, tímto přístupem přebíráte i komplet zodpovědnost (za problémy můžete nadávat akorát sobě) a vyžaduje to i větší znalosti IT.
Je plno stejně kvalitních či kvalitnějších alternativ, ale osobně mám drtivou většinu IOT senzorů / detektorů od značky Shelly. Doporučuji se ale podívat i na zařízení na bázi ZigBee. Já jsem ale žádnou centrální bránu řešit nechtěl a spoléhal se čistě na komunikaci po WiFi. Jelikož jde o novostavbu, stropních WiFi „talířů“ je po domě dostatek (Ubiquiti UniFi AC Long Range).
Zařízení „Shelly 1“ (či Shelly 1 Plus) v hodnotě několika stokorun slouží skvěle například na otevírání el. garážových vrat. Paradoxně to vychází finančně levněji, než dokupovat oficiální dálkové ovladače dalším členům rodiny. Navíc můžete vrata otevírat odkudkoliv přímo z mobilního telefonu.
Otevřené okno, děravá pračkaDále používám Shelly Door Window 2 a Shelly Flood. V obou případech jde o senzory napájené baterií. První detekuje otevřená okna / dveře a druhý únik vody. Detektory na otevřené okna / dveře používáme tam, kde je běžně zapomínáme v rámci větrání zavírat, tedy u oken a dvěří, které nejsou úplně na očích. Shelly Flood je pak umístěn pod pračkou a myčkou. S prorezlou myčkou a tekoucí pračkou máme z minulosti neblahé zkušenosti. Původně byl záměr zaintegrovat detektory vody společně s centrálním uzávěrem vody, ale ten jsem zkritizoval v předchozím díle (powered by Tuya) a už nikdy nedořešil. Pointa, že únik vody z myčky / pračky povede automaticky k uzavření přívodu vody do domu, tak dosud nebyla realizována.
Někdy je umění najít místo, kam senzor otevřených dveří přidělat. Oba díly musí být od sebe maximálně několik mm, pokud mají hlásit stav „zavřeno“. Zde toho bylo dosaženo držáky z 3D tisku.
Měrák elektriky i vodyDalší IOT zařízení, která používám, ale jsou spíše pasivního charakteru jsou:
Shelly 3EM – 3-fázový měřák spotřebované el. energie v domácnosti. Původně koupeno spíše jako hračka, nicméně nakonec se ukázalo, že to není úplně marná věc pro detekci anomálií ve spotřebě el. energie. Já tak díky tomuto měřáku včas odhalil, že tepelné čerpadlo nebylo nastaveno úplně ideálně (například, že zbytečně často využívalo neúspornou přímotopnou spirálu).
AI on the edge device – měřák spotřeby vody. Tohle není hotové zařízení, ale pokud za pár stovek koupíte miniaturní integrovanou desku s kamerou a správně ji nasadíte na vodoměr (nutno vytisknout na 3D tiskárně), dokáže spolehlivě převádět stav analogových „budíků“ na litry. A když se pak kouknete na denní spotřebu vody, nestačí se člověk divit. V m3 to nevypadá tak drasticky…
Bez 3D tiskárny se člověk neobejde ani zde. V horní části je umístěn „mini počítač“ na bázi ESP32 CAM se SW AI on the edge, který například co 5 minut vyfotí ciferníky vodoměru miniaturní kamerou (přisvítí si LEDkou) a převede je do digitální podoby.
Trouba a čistička vzduchu taky na internet?V domácnosti by se našlo více zařízení, která se chlubí možností připojení k internetu, ale nenašel jsem žádný rozumný scénář, proč bych je tam připojoval (trouba, čistička vzduchu, …). Naopak možnost vzdáleně zapnout klimatizaci, poštelovat tepelné čerpadlo či fotovoltaický systém je vítaná. U chytré televize s Androidem je varianta s internetem jasná.
Fotovoltaika značky SOLAX, stejně jako tepelné čerpadlo PZP (model Economic) mají též vlastní cloudovou infrastrukturu a tedy i mobilní aplikaci, nicméně nic z toho se mě netýká. Komunikace je tak vedena lokálně skrze „průmyslový“ protokol Modbus, který obě zařízení skrze síťový protokol TCP nabízejí.
Bez internetu, odříznuto, šmytecVšechna výše uvedená zařízení jsem laicky řečeno odříznul od internetu. To je alfa a omega odlišného přístupu, který jsem zvolil. Místo oficiální cloudové infrastruktury výrobců tak všechna zařízení směruju na lokální server s open source aplikací Home Assistant. Tahle aplikace umožňuje spravovat téměř vše, co je připojeno ethernetovým kabelem nebo skrze WiFi. A to z jednoho místa (resp. z jedné mobilní aplikace) a často lépe, než přes oficiální aplikace výrobců. Home Assistant provozuji na mini počítači Raspberry 3, protože se mě jich doma prostě několik válelo Variant nasazení ale existuje několik. Kromě toho, že můžete Home Assistant provozovat v režimu „hračička“, můžete v něm mezi připojenými zařízeními vytvářet i automatizace a optimalizovat tak chod domácnosti.
Chytrá IOT zařízení značky Shelly Vám detekuje Home Assistant automaticky během několika minut a jejich připojení je otázkou několika kliknutí. FVE SOLAX lze provozovat skrze protokol Modbus a díky existenci addonu je to i zde na několik kliknutí + nutnost zadat IP adresu střídače. Největší výzvou tak bylo připojení tepelného čerpadla PZP opět skrze Modbus (zvlášť, když tenhle protokol vidíte prvně v životě), ke kterému ale žádný addon neexistuje. Díky vstřícnému přístupu tech. podpory společnosti PZP jsem ale obdržel dokumentaci a několik dalších cenných rad, což vedlo k tomu, že dokážu vyčítat a měnit klíčové parametry tepelného čerpadla.
Home Assistant – z jednoho místa můžete vidět dění v celé domácnosti. Možnosti jsou obrovské. Příjemné je i udržování historie jednotlivých hodnot a hlavně to, že je HA dotaženější než celá řada originálních aplikací od výrobců IOT.
Nebýt otrokemAč prostřednictvím Home Assistantu přebírám kontrolu nad tepelným čerpadlem, neohrozím chod TP ani domácnosti v případě, že například server s Home Assistantem „umře“ nebo ho vypnu. V zimě to prostě bude topit tak jako tak a teplá voda taky bude. Obecně to mám takhle nastaveno i vůči dalším IOT zařízením. Garáž můžu pořád otevřít dálkovým ovladačem, světla vypínačem a dveře klíčem. Nechci být otrokem chytré domácnosti. Mimochodem (tohle má teda už hodně daleko od původního tématu ohledně zabezpečení IOT v domácnosti), v případě tepelného čerpadla mě zaujalo to (ač je to patrně normální, ale pro mě novinka, neboť jsem tuto problematiku nikdy neřešil), že se mu musíte v pravidelných intervalech (tuším že každých max. 100 sekund) z Home Assistantu skrze modbus hlásit. Jenom tak ho můžete vzdáleně z Home Assistantu ovládnout. Pokud se hlásit přestanete (například vlivem závady Home Assistant serveru), tepelko převezme řízení zpět. Jednoduché a funkční.
Automatizace na pár kliknutíJakmile máte všechna chytrá zařízení na jednom místě v Home Assistantu, můžete prostřednictvím vizuálních průvodců dělat i jinak složité věci jednoduše. Věci, které byste jinak museli řešit přes elektrikáře, nákupem fyzických stykačů, spínačů, …, dokážete vyřešit během pár minut přes klávesnici a myš. Já jsem kupříkladu v Home Assistantu realizoval tyto automatizace:
Akumulace / navýšení cílové teploty vody v bojleru v případě přebytků z fotovoltaiky
Automatizace je nastavena tak, že pokud fotovoltaika vyrábí více než 4 kW po dobu minimálně 20 minut (vyčteno přes modbus Solaxu), navýší významně cílovou teplotu v bojleru i za cenu, že začne tepelné čerpadlo využívat 3 kW přímotopnou spirálu (zařízeno přes modbus PZP). Asi by to šlo vymyslet sofistikovaněji, nicméně mě se předpověď počasí v HA neosvědčila, tudíž pokud moje FVE vyrábí 20 minut v kuse přes 4 kW, beru to, že venku je jasno s minimem mraků a tudíž je malá pravděpodobnost, že si bude tepelko při této operaci zbytečně „docucávat“ z baterie.
Okamžité shození tepelného čerpadla do pohotovostního režimu v případě výpadku el. energie ze sítě
Pokud vypadne el. síť v ulici (vyčteno z modbus Solaxu, který se přepne do režimu „off-grid“), nemá smyslu nahřívat vodu / topit z baterií (zařízeno skrze modbus PZP přehozením TČ do pohotovostního režimu). I v zimě je teplo v baráku naakumulované, tudíž pokud nenastal zrovna konec světa, těch pár minut až hodin, než elektrika naběhne, lze vydržet. Resp. než baterii FVE rychle vyždímat k dohřátí teplé vody a nebo ke zvýšení teploty topení, to ji raději využít k zajištění osvětlení, vaření či dokončení pracího cyklu. Pochopitelně funguje i opačná automatizace, která to po ukončení výpadku „nahodí“.
Zapnutí bazénové filtrace pokud jsou přebytky a venku je teplota, která za tu filtraci bazénu stojí
Elektromobil, spotové ceny, závěrPokud pak někdo nakupuje energii za spotové ceny, řeší i její prodej a vlastní elektromobil / wallbox, pak lze vymyslet spousty dalších automatizací. To všechno lze totiž do Home Assistantu integrovat.
No a v příští (a zřejmě poslední) části se teda už opravdu vrátíme k tomu zabezpečení Home Assistant sice v tomto díle spatřil světlo světa, ale těžko si přes něj otevřeme garážová vrata, pokud budeme před domem mimo dosah WiFi signálu. Čekají nás tak pojmy jako VLAN, pfSense, HAproxy, Snort, Acme, GeoIp blocking, fail2ban, …
The post Odříznutí internetu, přesun k Home Assistantu appeared first on VIRY.CZ.
Kategorie: Viry a Červi
DSA-5554 postgresql-13
security update
Kategorie: GNU/Linux & BSD, Security Vulnerabilities & Exploits
DSA-5553 postgresql-15
security update
Kategorie: GNU/Linux & BSD, Security Vulnerabilities & Exploits
DSA-5549 trafficserver
security update
Kategorie: GNU/Linux & BSD, Security Vulnerabilities & Exploits
- « první
- ‹ předchozí
- …
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- následující ›
- poslední »

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
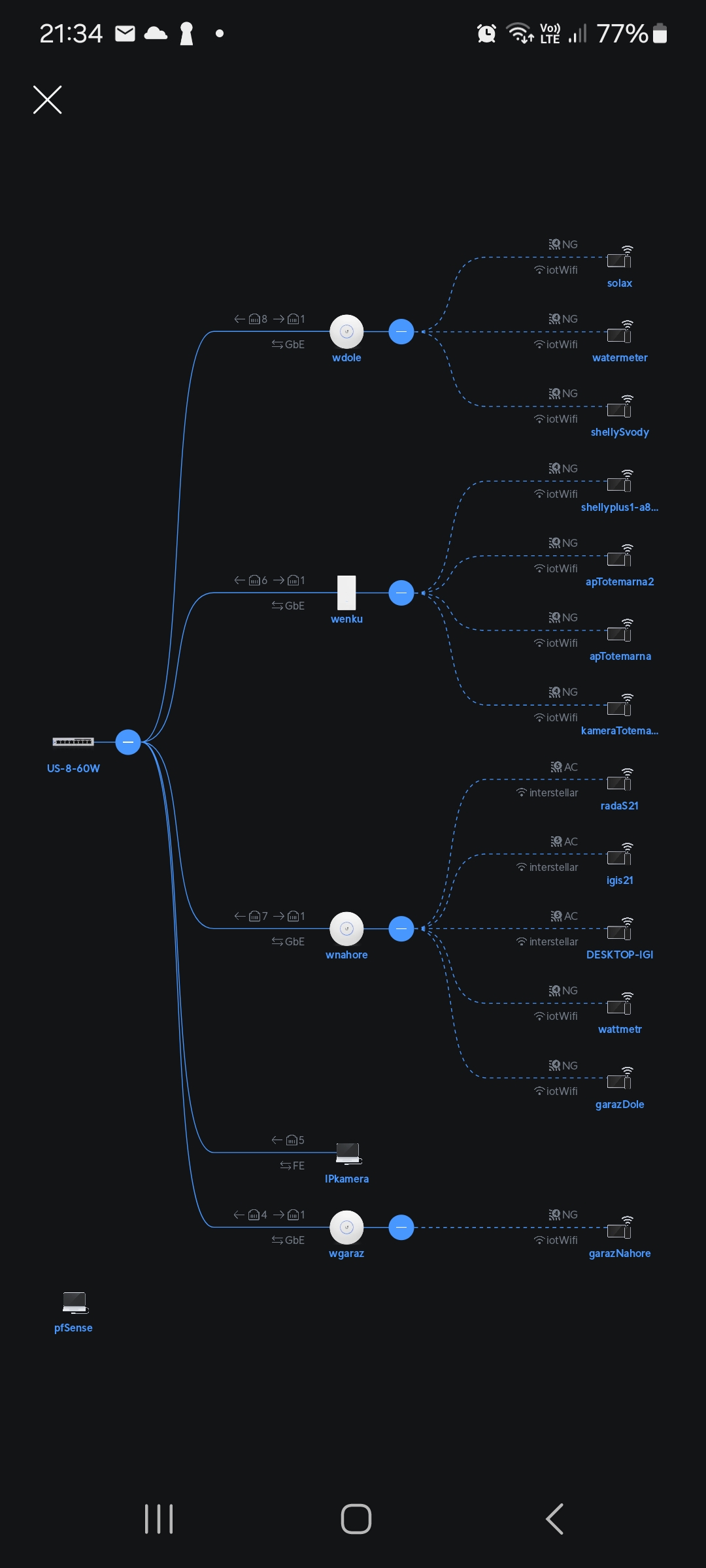{kind=link}